

The popularity of Apache Kafka has never been greater. Originally created by LinkedIn, and now an open-source project maintained by Confluent, Kafka is a community distributed event-streaming platform capable of handling trillions of events daily. Its appeal stems from how it allows users to decouple data streams and their systems.
Source systems, including transaction systems and event producers, supply their data to Kafka; target systems, such as databases and analytical systems, source their data directly from it. It therefore enables communication between producers and consumers via message-based topics.
In this article we seek to outline what Kafka is and how it is comprised. By understanding how each component within Kafka works, we can learn about the different configurations that can be applied to Producers and Consumers, as well as how this can be tweaked to get the best out of Kafka. We also share information on optimizing throughput and latency through configurations such as Idempotent Producers and Message Compressions. Finally, we provide an overview of how to set up Kafka, create Topics, and produce and consume messages from them.
Contents
- Introduction
- Kafka’s characteristics and use cases
- The core componentry and workings of Kafka
- Additional Kafka configurations
- How to set up and run Kafka
Kafka’s characteristics and use cases
Kafka is used by thousands of firms worldwide, including more than 30% of Fortune 500 companies.
Its key characteristics include being distributed and fault-tolerant; its resilient architecture, meaning it can recover from node failures automatically; its horizontal scalability, up to hundreds of brokers and millions of messages per second; and its high performance, with latency of less than 10ms, meaning that Kafka operates in real time.
Adoption of Kafka has also been driven by its adaptability both to modern-day, distributed or complex systems as well as to legacy systems. Four key use cases within these systems include Messaging, Metrics, Big Data Ingestion, and Log Aggregation:
Kafka can replace a more traditional message broker, particularly within large-scale message processing systems, offering better throughput, built-in partitioning, replication, and fault-tolerance. It can also be used to monitor data, aggregating statistics from distributed applications to produce centralized feeds of operational data.
In the world of Big Data, it is common to use Kafka as an ‘Ingestion Buffer’, making use of the various connectors available that sink data from Kafka to HDFS, S3, or Elastic Search. Finally, one of the most common use cases of Kafka is as a log aggregation solution, receiving log files from servers and organizing them in a central location (such as a file server or HDFS) for processing.
The core componentry and workings of Kafka
In Kafka, messages are organized and durably stored in Topics. Topics can be visualized as folders in the filesystem; messages are files in that folder. Messages can be read from Topics as often as required and do not get deleted upon consumption. There is no limit to the number of Topics in Kafka, and each one is identified by a name typically based on the nature of the stream of data it is carrying.
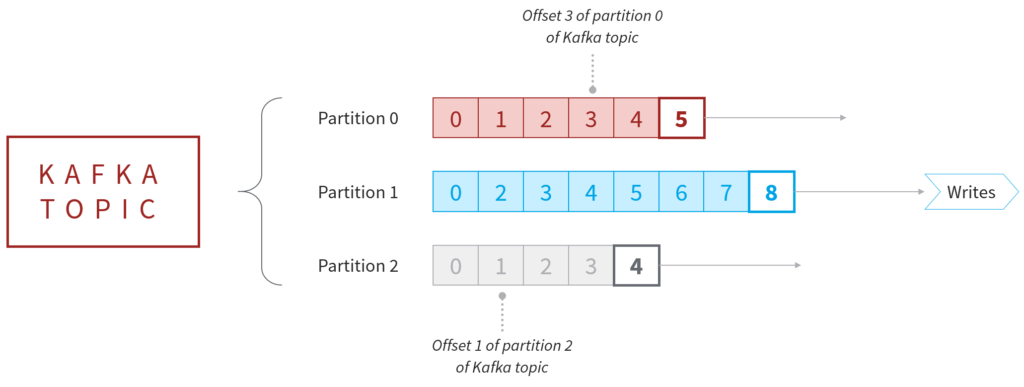
Topics are then split into Partitions. The constituent Partitions of each Topic are spread over the buckets located on different Brokers (see below). Once data is written to the Partition, it cannot be altered. Messages stored in Partitions appear in a fixed order.
Each message within a Partition gets an incremental ID called an Offset. A message within a Partition is located as Offset 3 in Partition 0 of Topic X, for example. New messages written to a Partition are located at the end, with the Offset increasing by an increment of 1.
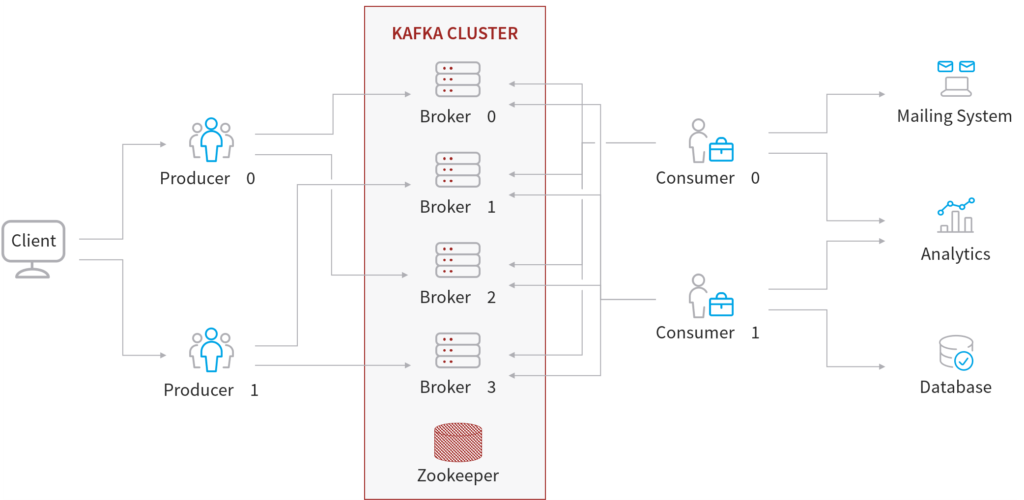
A Kafka cluster is composed of multiple Brokers, or servers. Each Broker is identified with its own individual ID, which is always integer (rather than string). Each Broker contains certain Topic Partitions. Once connected to one of the Brokers, you can connect to any other Broker within the entire cluster via this initial starting point, known as a Bootstrap Broker.
A replication factor is the number of copies of data held over multiple Brokers. Its value should always be greater than 1 – typically 2 to 3, to ensure the availability of data in the event of Broker node failure.
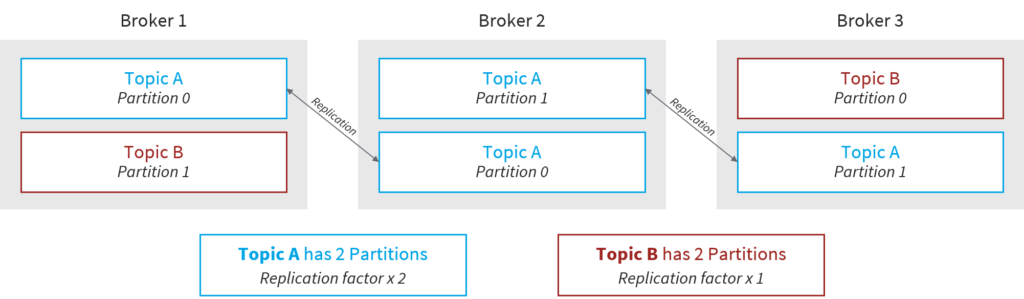
In the diagram above, Topic A has a replication factor of 2, which means that each Partition within the Topic will be replicated to two Broker nodes. Topic B has a replication factor of 1, meaning that each of its Partitions will be available to only one Broker node and data loss can happen in the event of node failure.
Only one Broker can be a leader for a Partition at any given time. This means only that leader Broker can receive or serve data for that Partition. The additional Brokers will synchronize the data with the leader. Each Partition will have one leader and multiple in-sync replicas (ISRs).
ZooKeeper manages Brokers, including by maintaining the list of Brokers within a cluster, performing leader elections for Partitions, and notifying Kafka of any changes – for example, if a Broker is down or up or a new Topic has been created or deleted. Currently, Kafka cannot work without ZooKeeper, but Confluent is working on replacing it with Self-Managed Metadata Quorum.
Producers are the client applications that publish messages to Topics. There can be multiple Producers sending Messages to the same Topic. Producers know to which Topic and to which Partition data needs to be sent. The I/O is performed for the Producer by the relevant Broker node.
Producers can choose to receive acknowledgment of the data written to Brokers. There are 3 possible acks values that can be set:
- acks=0: Producer will not wait for acknowledgement. (Data may be lost.)
- acks=1: Producer will wait for Leader’s acknowledgment. (Limited data loss.)
- acks=2: Producer will wait for Leader + Replicas’ acknowledgment. (No data loss.)
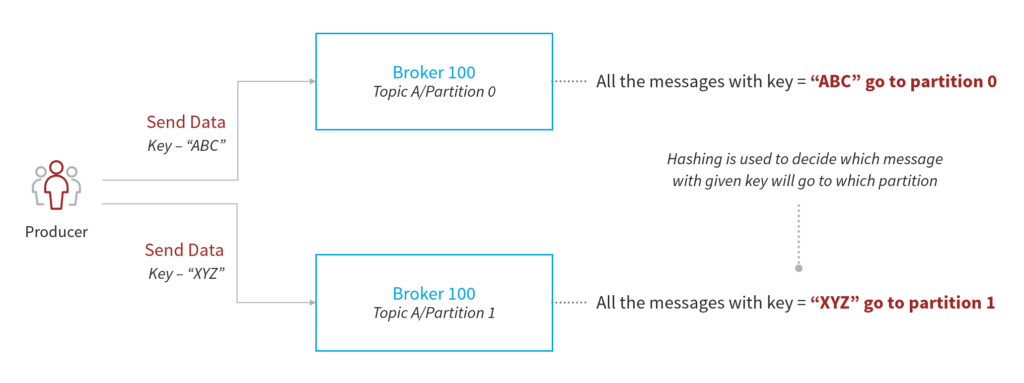
Producers can also choose to send keys with the messages, in either string or integer. If the key is NULL, the data will be sent in round-robin fashion to each Partition. If a key is sent, messages with the same key will always go to the same Partition.
Finally, Consumers are the client applications that read, process, and send on messages from the Topics to which they are subscribed. Consumers read data from a known Broker in an order pre-set within each Partition.
A Consumer Group can be created when there are multiple consumers, with each Consumer within the group reading from an exclusive Partition. For example, if there are three Partitions within a Topic and two Consumers, Consumer-1 will read data from Partition-0 and Partition-1 and Consumer-2 will read from Partition-2. Once the Group has been assigned, a Consumer will only be able to access data from the same Partition(s) – unless any of the Consumers within the Group go down, which results in rebalancing and Partitions being re-assigned to the available Consumers.
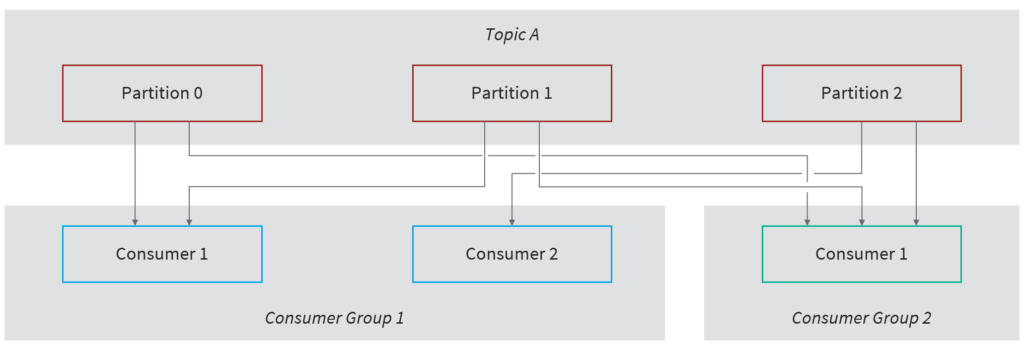
Kafka stores the Offsets at which a Consumer Group has been reading. When a Consumer has successfully processed the message received from Kafka, it commits the Offset in a Topic named _consumer_offsets. If the Consumer dies, it can read data back from where it left earlier. There are three delivery semantics that Consumers can choose for when to commit the Offset:
- At most once: Offsets are committed as soon as the message is received. If the processing goes wrong, the message will be lost.
- At least once: Offsets are committed after the message is processed. If the processing goes wrong, the message can be read again.
- Exactly once: Can be achieved for Kafka > different workflows using Kafka Stream APIs.
Additional Kafka configurations: Idempotent Producers, Message Compression, Segments, & Log Cleanup Policies
From Kafka 1.1 onwards, an ‘Idempotent Producer’ is defined as one that won’t produce duplicate data in case of network error. Idempotent Producers can be used only when acks are set to “all”.
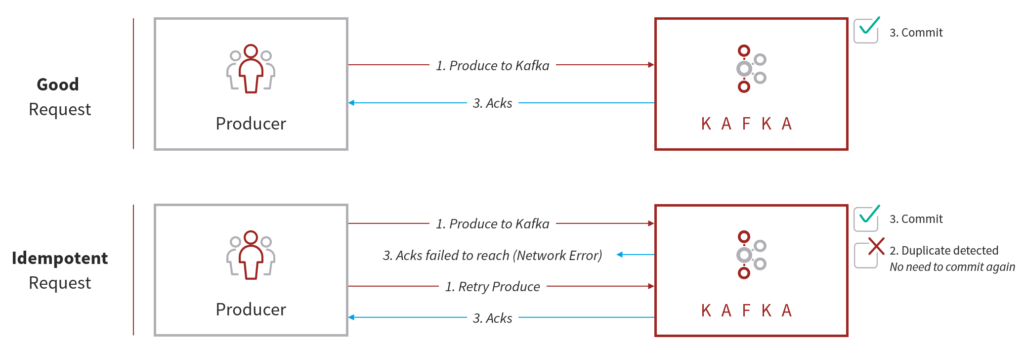
As displayed in the diagram above, in a ‘Good Request’ the Producer produces the message and sends to Kafka, Kafka commits the message and sends an acknowledgement to the Producer, and the Producer successfully receives the acknowledgment.
In an ‘Idempotent Request’, the Producer produces the messages and sends to Kafka. Kafka then commits the messages and sends an acknowledgement to the Producer. However, the Producer does not receive the acknowledgement. In this case, the Producer will retry to produce the same message. Since that message was already committed the first time, it will not be committed again and only an acknowledgement will be sent.
To make the Producer Idempotent, the following property must be set at the Producer:
“enable.idempotence”: true
Running an Idempotent Producer can impact throughput and latency and should therefore always be tested with the use-case before being fully implemented.
Producers usually send data in text format, such as through Json, Text, or Avro. In these instances, it is important to apply Message Compression to the Producer. Compression is enabled at the Producer level and does not require any configuration change at the Broker or the Consumer level. It is a highly effective technique for bigger batches of messages.
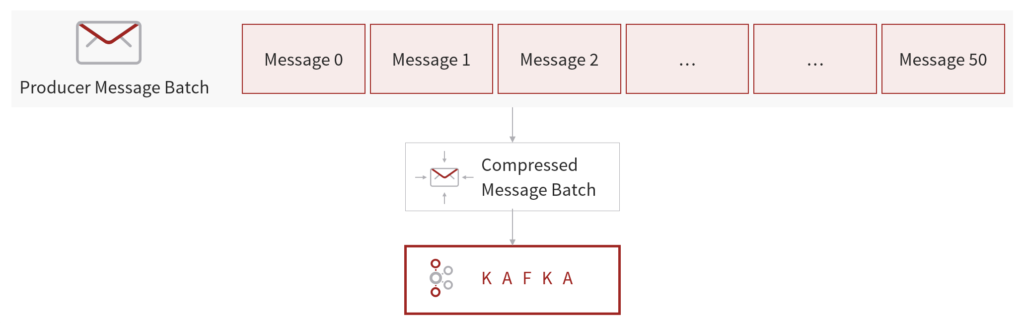
Compression reduces the size of the request and the volume of network traffic, enables faster, lower-latency data transfer over the network, and delivers better throughput. The trade-off is that compression at the Producer end and decompression at the Consumer end requires extra CPU cycles.
The following property needs to be set to enable compression at Producer level. The default is set to ‘none’:
“compression.type” : ‘none’ , ‘gzip’, ‘snappy’, ‘lz4’
Much like how Topics are made up of Partitions, Partitions are made up of Segments (i.e. files). Each Segment within a Partition will have a range of Offsets. Only one Segment is ever active within a Partition – the one to which data is being written.
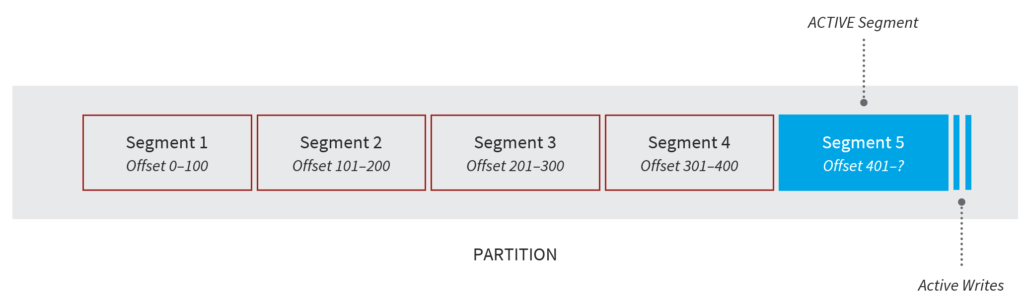
There are two Segment-related configurations:
- log.segment.bytes: the maximum size of the single segment in bytes
- log.segment.ms: the time Kafka will wait before committing the segment if not full
Finally, Log Cleanup means expiring the data or messages within the Kafka cluster. Deleting messages from Kafka allows greater control over the size of the messages on the disk and limits the maintenance work required in the Kafka cluster. However, Log Cleanup should not happen too frequently as it utilizes CPU and RAM.
There are two policies that can be applied:
- Policy-1: “log.cleanup.policy=delete”:
- A default policy for all the user Topics. Message is deleted on the basis of its age.
- By default, a Message will be deleted after one week. This can be tweaked by setting the following property: log.retention.hours
- Deletion can also be triggered depending upon the maximum size of the log (default is infinity). This can be tweaked by setting the following property: log.retention.bytes
- Policy-2: “log.cleanup.policy=compact”:
- A default policy for the _consumer_offsets Topic. Message is deleted on the basis of its key, with all the duplicate keys deleted. The following properties can be configured:
- Segment.hours (default 7 days): Maximum time to wait to close active Segment.
- Segment.bytes (default 1 G): Maximum size of segment.
- Min.compaction.lag.ms (default 0): How long to wait before Message is compacted.
- Delete.retention.ms (default 24 hours): How long to wait before deleting data marked for compaction.
- A default policy for the _consumer_offsets Topic. Message is deleted on the basis of its key, with all the duplicate keys deleted. The following properties can be configured:
How to set up and run Kafka
Setting up and running Kafka is straightforward for Mac or Linux users. For Windows users, some issues may occur. We recommended using Docker with Linux image.
- Download Kafka
Kafka can be downloaded here. Once downloaded, you need to extract the Binary. - Starting Zookeeper
Run the following command:
zookeeper-server-start.sh config/zookeeper.properties - Starting Kafka
Run the following command:
kafka-server-start.sh config/server.properties - Configuring Topics
The following are commands to create, describe, list, and delete Topics.- Create Topic: kafka-topics.sh — zookeeper 127.0.0.1:2181 — topic demo_topic — create — Partitions 3 — replication-factor 1
This is an example of creating a Topic with name “demo_topic” with three Partitions and a replication factor of 1. - Describe Topic: kafka-topics.sh — zookeeper 127.0.0.1:2181 — topic demo_topic — describe
To describe the configuration of the Topic - List All Topics: kafka-topics.sh — zookeeper 127.0.0.1:2181 — list
- Delete Topic: kafka-topics.sh — zookeeper 127.0.0.1:2181 — topic demo_topic — delete
To delete the demo_topic
- Create Topic: kafka-topics.sh — zookeeper 127.0.0.1:2181 — topic demo_topic — create — Partitions 3 — replication-factor 1
- Starting Producer
Run the following command:
kafka-console-producer.sh — broker-list 127.0.0.1:9092 — topic demo_topic — producer-property acks=all - Starting Consumer
Run the following command:
kafka-console-consumer.sh — bootstrap-server 127.0.0.1:9092 — topic first_topic
This starts the Consumer that will read data from Topic “demo_topic”.